
Указатель — это переменная, содержащая адрес переменной. Указатели широко применяются в Си — отчасти потому, что в некоторых случаях без них просто не обойтись, а отчасти потому, что программы с ними обычно короче и эффективнее. Указатели и массивы тесно связаны друг с другом; в этой главе мы рассмотрим эту зависимость и покажем, как ею пользоваться.
Наряду с goto указатели когда-то были объявлены лучшим средством для
написания малопонятных программ. Так оно и есть, если ими пользоваться
бездумно. Ведь очень легко получить указатель, ссылающийся на что-нибудь
совсем нежелательное. При соблюдении же определенной дисциплины с помощью
указателей можно достичь ясности и простоты. Мы попытаемся убедить вас в
этом.
Изменения, внесенные стандартом ANSI, связаны в основном с формулированием
точных правил работы с указателями. Он узаконил накопленный положительный
опыт программистов и удачные нововведения разработчиков компиляторов. Кроме
того, взамен char * в качестве типа обобщенного указателя предлагается тип
void * (указатель на void).
Начнем с того, что рассмотрим упрощенную схему организации памяти. Память
типичной машины представляет собой массив последовательно пронумерованных и
проадресованных ячеек, с которыми можно работать по отдельности или связными
кусками. Применительно к любой машине верны следующие утверждения: один байт
может хранить значение типа char, двухбайтовые ячейки могут рассматриваться
как целое типа short, а четырехбайтовые — как целые типа long. Указатель —
это группа ячеек (как правило, две или четыре), в которых может храниться
адрес. Так, если c имеет тип char, а p — указатель, ссылающийся на c, то
ситуация выглядит следующим образом:
Унарный оператор & выдает адрес объекта, так что инструкция
p = &c;
присваивает адрес ячейки с переменной p (говорят, что p указывает на с или,
что то же, p ссылается на c). Оператор & применяется только к объектам,
расположенным в памяти: к переменным и элементам массивов. Его операндам не
может быть ни выражение, ни константа, ни регистровая переменная.
Унарный оператор * есть оператор раскрытия ссылки. Примененный к указателю он
выдает объект, на который данный указатель ссылается. Предположим, что x и y
— целые, а ip — указатель на int. Следующие несколько строк придуманы
специально для того, чтобы показать, каким образом декларируются указатели и
используются операторы & и *.
int x = 1, y = 2, z[10]; int *ip; /* ip - указатель на int */ ip = &x; /* теперь ip указывает на x */ y = *ip; /* y теперь равен 1 */ *ip = 0; /* x теперь равен 0 */ ip = &z[0]; /* ip теперь указывает на z[0] */
Декларации x, y и z нам уже знакомы. Декларацию указателя ip
int *ip;
мы стремились сделать мнемоничной — она гласит: «выражение *ip есть нечто
типа int». Синтаксис декларации переменной «подстраивается» под синтаксис
выражений, в которых эта переменная может встретиться. Указанный принцип
применим и в отношении описаний функций. Например, запись
double *dp, atof(char *);
означает, что выражение *dp и atof(s) имеют тип double, а аргумент функции
atof есть указатель на char.
Вы, наверное, заметили, что указателю разрешено ссылаться только на объекты
заданного типа. (Существует одно исключение: «указатель на void» может
ссылаться на объекты любого типа, но к такому указателю нельзя применять
оператор раскрытия ссылки. Мы вернемся к этому в разд. 5.11.)
Если ip ссылается на x целого типа, то *ip можно использовать в любом месте,
где допустимо применение x; например,
*ip = *ip + 10;
увеличивает *ip на 10.
Унарные операторы * и & имеют более высокий приоритет, чем арифметические
операторы, так что присваивание
y = *ip + 1
берет то, на что указывает ip, и добавляет к нему 1, а результат присваивает
переменной y. Аналогично
*ip += 1
увеличивает на единицу то, на что ссылается ip; те же действия выполняют
++*ip
и
(*ip)++
В последней записи скобки необходимы, поскольку, если их не будет, увеличится
значение самого указателя, а не то, на что он ссылается. Это обусловлено
тем, что унарные операторы * и ++ имеют одинаковые приоритет и порядок
выполнения — справа налево.
И наконец, так как указатели сами являются переменными, в тексте они могут
встречаться и без оператора раскрытия ссылки. Например, если iq есть другой
указатель на int, то
iq = ip
копирует содержимое ip в iq, чтобы ip и iq ссылались на один и тот же объект.
Поскольку функции в Си в качестве своих аргументов получают значения
параметров, прямой возможности, находясь в вызванной функции, изменить
переменную вызывающей функции нет. В программе сортировки нам понадобилась
функция swap, переставляющая местами два неупорядоченных элемента. Однако
недостаточно написать
swap(a, b);
где функция swap определена следующим образом:
void swap(int x, int y) /* НЕВЕРНО */
{
int temp;
temp = x;
x = y;
y = temp;
}
Поскольку swap получает лишь копни значений переменных a и b, она не может
повлиять на переменные a и b той программы, которая к ней обратилась.
Чтобы получить желаемый эффект, надо вызывающей программе передать указатели на те значения, которые должны быть изменены:
swap(&a, &b);
Так как оператор & получает адрес переменной, &a есть указатель на a. В самой
функции swap параметры должны быть описаны как указатели, при этом доступ к
значениям параметров будет осуществляться через них косвенно.
void swap(int *px, int *py) /* перестановка *px и *py */
{
int temp;
temp = *px;
*px = *py;
*py = temp;
}
Графически это можно изобразить следующим образом:
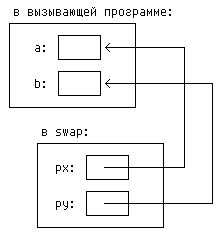
Аргументы-указатели позволяют функции осуществлять доступ к объектам
вызвавшей ее программы и дают ей возможность изменить эти объекты.
Рассмотрим, например, функцию getint, которая осуществляет ввод в свободном
формате одного целого числа и его перевод из текстового представления в
значение типа int. Функция getint должна возвращать значение полученного
числа или сигнализировать значением EOF о конце файла, если входной поток
исчерпан. Эти значения должны возвращаться по разным каналам, так как нельзя
рассчитывать на то, что полученное в результате перевода число никогда не
совпадет с EOF.
Одно из решений состоит в том, чтобы getint выдавала характеристику состояния
файла (исчерпан или не исчерпан) в качестве результата, а значение самого
числа помещала согласно указателю, переданному ей в виде аргумента. Похожая
схема действует в программе scanf, которую мы рассмотрим в разд. 7.4.
Показанный ниже цикл заполняет некоторый массив целыми числами, полученными с
помощью getint.
int n, array[SIZE], getint(int *);
for (n = 0; n < SIZE && getint(&array[n]) != EOF; n++)
;
Результат каждого очередного обращения к getint посылается в array[n], и n
увеличивается на единицу. Заметим, что существенным здесь является то, что
функции getint передается адрес элемента array[n]. Если этого не сделать, у
getint не будет способа вернуть в вызывающую программу переведенное целое
число.
В предлагаемом нами варианте функция getint выдает EOF по концу файла; нуль,
если следующие вводимые литеры не представляют собою числа; и положительное
значение, если введенные литеры есть правильное число.
#include <ctype.h>
int getch(void);
void ungetch(int);
/* getint: читает следующее целое из ввода в *pn */
int getint(int *pn)
{
int c, sign;
while (isspace(c = getch()))
; /* пропуск пробельных литер */
if (!isdigit(c) && c != EOF && c != '+' && c != '-') {
ungetch(c); /* не число */
return 0;
}
sign = (c == '-') ? -1 : 1;
if (c == '+' || c == '-')
c = getch();
for (*pn = 0; isdigit(c); c = getch())
*pn = 10 * *pn + (c - '0');
*pn *= sign;
if (c != EOF)
ungetch(c);
return c;
}
Везде в getint под комбинацией *pn подразумевается обычная переменная типа
int. Функция ungetch вместе с getch (разд. 4.3) включена в программу, чтобы
обеспечить возможность отослать назад лишнюю прочитанную литеру.
Функция getint написана так, что знаки - или +, за которыми
не следует цифра, она понимает как «правильное» представление нуля.
Скорректируйте программу таким образом, чтобы она в подобных случаях
возвращала прочитанный знак назад во ввод.
Напишите функцию getfloat — аналог getint для чисел с
плавающей точкой. Какой тип будет иметь результирующее значение, выдаваемое
функцией getfloat?
В Си существует связь между указателями и массивами, и связь эта настолько тесная, что эти средства лучше рассматривать вместе. Любой доступ к элементу массива, осуществляемый операцией индексирования, может быть выполнен при помощи указателя. Вариант с указателями в общем случае работает быстрее, но разобраться в нем, особенно непосвященному, довольно трудно.
Декларация
int a[10];
определяет массив a размера 10, т.е. блок из 10 последовательных
объектов с именами a[0], a[1], ..., a[9].

Запись а[i] отсылает нас к i-му элементу массива. Если pa есть указатель на
int, т.е. определен как
int *pa;
то в результате присваивания
pa = &a[0];
pa будет указывать на нулевой элемент a; иначе говоря, pa будет содержать
адрес элемента a[0].
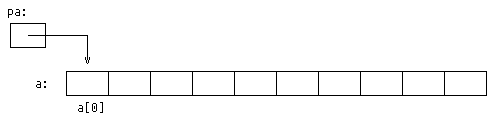
Теперь присваивание
x = *pa;
будет копировать содержимое a[0] в x.
Если pa указывает на некоторый элемент массива, то pa+1 по определению
указывает на следующий элемент, pa+i — на i-й элемент после pa, а pa-i — на
i-й элемент перед pa. Таким образом, если pa указывает на a[0], то
*(pa+1)
есть содержимое a[1], pa+i — адрес a[i], а *(pa+i) — содержимое a[i].
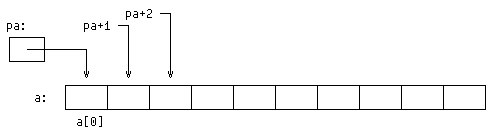
Сделанные замечания верны безотносительно к типу и размеру элементов массива
a. Смысл слов «добавить 1 к указателю», как и смысл любой арифметики с
указателями, в том, чтобы pa+1 указывал на следующий объект, а pa+i — на i-й
после pa.
Между индексированием и арифметикой с указателями существует очень тесная связь. По определению значение переменной или выражения типа массив есть адрес нулевого элемента массива. После присваивания
pa = &a[0];
pa и a имеют одно и то же значение. Поскольку имя массива есть не что иное,
как адрес его начального элемента, присваивание pa=&a[0]; можно также
записать в следующем виде:
pa = a;
Еще более удивительно (по крайней мере на первый взгляд) то, что a[i] можно
записать как *(a+i). Встречая запись a[i], компилятор сразу преобразует ее в
*(a+i); указанные две формы записи эквивалентны. Из этого следует, что
полученные в результате применения оператора & записи &a[i] и a+i также будут
эквивалентными, т.е. и в том и в другом случае это адрес i-го элемента после
a. С другой стороны, если pa — указатель, то в выражениях его можно
использовать с индексом, т.е. запись pa[i] эквивалентна записи *(pa+i).
Элемент массива одинаково разрешается изображать и в виде указателя со
смещением и в виде имени массива с индексом.
Между именем массива и указателем, выступающим в роли имени массива,
существует одно различие. Указатель — это переменная, поэтому можно написать
pa = a или pa++. Но имя массива не является переменной, и записи типа a = pa
или a++ не допускаются.
Если имя массива передается функции, то последняя получает в качестве
аргумента адрес его начального элемента. Внутри вызываемой функции этот
аргумент является локальной переменной, содержащей адрес. Мы можем
воспользоваться отмеченным фактом и написать еще одну версию функции strlen,
вычисляющей длину стринга.
/* strlen: возвращает длину стринга */
int strlen(char *s)
{
int n;
for (n = 0; *s != '\0'; s++)
n++;
return n;
}
Так как переменная s — указатель, к нему применима операция ++; s++ никакого
влияния на стринг литер функции, которая обратилась к strlen, не оказывает.
Просто увеличивается на 1 некоторая копия указателя, находящаяся в личном
пользовании функции strlen. Это значит, что все вызовы типа:
strlen("Здравствуй, мир"); /* стринговая константа */
strlen(array); /* char array[100]; */
strlen(ptr); /* char *ptr; */
законны.
Записи
char s[];
и
char *s;
в определении функции в качестве формальных параметров эквивалентны. Мы
отдаем предпочтение последней, поскольку она более явно сообщает, что s есть
указатель. Если функции в качестве аргумента передается имя массива, то она
может рассматривать его так, как ей удобно — либо как имя массива, либо как
указатель, и поступать с ним соответственно. Она может даже использовать оба
вида записи, если это покажется ей уместным.
Функции можно передать часть массива, для этого аргумент должен указывать на
начало подмассива. Например, если a — массив, то в записях
f(&a[2])
или
f(a+2)функции
f передается адрес подмассива, начинающегося с элемента a[2]. Внутри
функции f описание параметров может выглядеть как
f(int arr[]) { ... }
или
f(int *arr) { ... }
Следовательно, для f тот факт, что параметр ссылается на часть массива, а не
на весь массив, не имеет значения.
Если есть уверенность, что элементы массива существуют, то возможно
индексирование и в «обратную» сторону по отношению к нулевому элементу;
выражения p[-1], p[-2] и т.д. не противоречат синтаксису языка и ссылаются на
элементы, стоящие непосредственно перед p[0]. Разумеется, нельзя «выходить»
за границы массива и тем самым ссылаться на несуществующие «объекты».
Если p есть указатель на некоторый элемент массива, то p++ продвигает p так,
чтобы он указывал на следующий элемент, а p += i увеличивает его, чтобы он
указывал на i-й элемент после того, на который он указывал ранее. Эти и
подобные конструкции — самые простые примеры арифметики над указателями,
называемой также адресной арифметикой.
Си последователен и единообразен в своем подходе к адресной арифметике. Это
соединение в одном языке указателей, массивов и адресной арифметики — одна из
сильных его сторон. Проиллюстрируем сказанное построением простого
распределителя памяти, состоящего из двух программ. Первая, alloc(n),
возвращает указатель p на n последовательно расположенных ячеек типа char;
программой, обращающейся к alloc, эти ячейки могут быть использованы для
запоминания литер. Вторая, afree(p), освобождает память для, возможно,
повторной, ее утилизации. Простота алгоритма обусловлена предположением, что
обращения к afree делаются в обратном порядке по отношению к соответствующим
обращениям к alloc. Таким образом, память, с которой работают alloc и afree,
является стеком (списком, в основе которого лежит принцип «последним вошел,
первым ушел»). В стандартной библиотеке имеются функции malloc и free,
которые делают то же самое, только без упомянутых ограничений; в разд. 8.7 мы
покажем, как они выглядят.
Функцию alloc легче всего реализовать, если условиться, что она будет
выдавать куски некоторого большого массива типа char, который мы назовем
allocbuf. Этот массив отдадим в личное пользование функциям alloc и afree.
Так как они имеют дело с указателями, а не с индексами массива, то другим
программам знать его имя не нужно. Кроме того, этот массив можно определить в
том же исходном файле, что и alloc и afree, объявив его с классификатором
static, благодаря чему он станет невидимым вне этого файла. На практике такой
массив может и вовсе не иметь имени, поскольку его можно запросить с помощью
malloc у операционной системы и получить указатель на некоторый безымянный
блок памяти.
Естественно, нам нужно знать, сколько элементов массива allocbuf уже занято.
Мы введем указатель allocp, который будет указывать на первый свободный
элемент. Если запрашивается память для n литер, то alloc возвращает текущее
значение allocp (т.е. адрес начала свободного блока) и затем увеличивает его
на n, чтобы указатель allocp ссылался на следующую свободную область. Если же
пространства нет, то alloc выдает нуль. Функция afree(p) просто устанавливает
в allocp значение p, если оно не выходит за пределы массива allocbuf.
Перед вызовом alloc:

После вызова alloc:

#define ALLOCSIZE 10000 /* размер доступного пространства */
static char allocbuf[ALLOCSIZE]; /* память для alloc */
static char *allocp = allocbuf; /* ук-ль на своб. место */
/* возвращает указатель на n литер */
char *alloc(int n)
{
if (allocbuf + ALLOCSIZE - allocp >= n) {
allocp += n; /* пространство есть */
return allocp - n; /* старое p */
}
else /* пространства нет */
return 0;
}
/* освобождается память по ук-лю p */
void afree(char *p)
{
if (p >= allocbuf && p < allocbuf + ALLOCSIZE)
allocp = p;
}
Как и любую другую переменную, указатель можно инициализировать, но только такими осмысленными для него значениями, как нуль или выражение, приводящее к некоторому адресу ранее определенных данных соответствующего типа. Декларация
static char *allocp = allocbuf;
определяет allocp как указатель на char и инициализирует его адресом массива
allocbuf, поскольку перед началом работы программы массив allocbuf пуст.
Указанная декларация могла бы иметь и такой вид:
static char *allocp = &allocbuf[0];
поскольку имя массива и есть адрес его нулевого элемента.
Проверка
if (allocbuf + ALLOCSIZE - allocp >= n) {
контролирует, достаточно ли пространства, чтобы удовлетворить запрос на n
литер. Если памяти достаточно, то новое значение для allocp должно указывать
не далее чем на следующую позицию за последним элементом allocbuf. При
выполнении этого требования alloc выдает указатель на начало выделенного
блока литер (обратите внимание на описание типа самой функции). Если
требование не выполняется, функция alloc должна выдать какой-то сигнал о том,
что памяти не хватает. Си гарантирует, что нуль никогда не будет правильной
ссылкой на данные, поэтому мы будем использовать его в качестве признака
аварийного события, в нашем случае нехватки памяти.
Указатели и целые не являются взаимозаменяемыми объектами. Константа нуль —
единственное исключение из этого правила: ее можно присвоить указателю, и
указатель можно сравнить с нулевой константой. Чтобы показать, что нуль —
это специальное значение для указателя, вместо цифры нуль, как правило,
записывают NULL — константу, определенную в файле <stdio.h>. С этого момента
и мы будем ею пользоваться.
Проверки
if (allocbuf + ALLOCSIZE - allocp >= n) {
и
if (p >= allocbuf && p < allocbuf + ALLOCSIZE)
демонстрируют несколько важных свойств арифметики с указателями. Во-первых, при соблюдении некоторых правил указатели можно сравнивать.
Если p и q указывают на элементы одного массива, то к ним можно применять
операторы отношения ==, !=, <, >= и т.д. Например, отношение вида
p < q
истинно, если p указывает на более ранний элемент массива, чем q. Любой
указатель всегда можно сравнить на равенство и неравенство с нулем. А вот для
указателей, ссылающихся на элементы разных массивов, результат арифметических
операций или сравнений не определен. (Существует одно исключение: в
арифметике с указателями можно использовать адрес несуществующего «следующего
за массивом» элемента, т.е. адрес того «элемента», который станет последним,
если в массив добавить еще один элемент.)
Во-вторых, как вы уже, наверное, заметили, указатели и целые можно складывать и вычитать. Запись вида
p + n
означает адрес объекта, занимающего n-е место после объекта, на который
указывает p. Это справедливо безотносительно к типу объекта, на который
ссылается p; n автоматически домножается на коэффициент, соответствующий
размеру объекта. Информация о размере неявно присутствует в описании p. Если,
к примеру, int занимает четыре байта, то коэффициент умножения будет равен
четырем.
Допускается также вычитание указателей. Например, если p и q ссылаются на
элементы одного массива и p < q, то q - p + 1 есть число элементов от p до q
включительно. Этим фактом можно воспользоваться при написании еще одной
версии strlen:
/* strlen: возвращает длину стринга s */
int strlen(char *s)
{
char *p = s;
while (*p != '\0')
p++;
return p - s;
}
В своем определении p инициализируется значением s, т.е. вначале p указывает
на первую литеру стринга. На каждом шаге цикла while проверяется очередная
литера; цикл продолжается до тех пор, пока не встретится '\0'. Каждое
продвижение указателя p на следующую литеру выполняется инструкцией p++, и
разность p-s дает число пройденных литер, т.е. длину стринга. (Число литер в
стринге может быть слишком большим, чтобы хранить его в переменной типа int.
Тип ptrdiff_t, достаточный для хранения разности (со знаком) двух указателей,
определен в головном файле <stddef.h> Однако, если быть очень осторожными,
нам следовало бы для возвращаемого результата использовать тип size_t, в этом
случае наша программа соответствовала бы стандартной библиотечной версии. Тип
size_t есть тип беззнакового целого, возвращаемого оператором sizeof.)
Арифметика с указателями учитывает тип: если она имеет дело со значениями
float, занимающими больше памяти, чем char, и p — указатель на float, то p++
продвинет p на следующее значение float. Это значит, что другую версию alloc,
которая имеет дело с элементами типа float, а не char, можно получить простой
заменой в alloc и afree всех char на float. Все операции с указателями будут
автоматически откорректированы в соответствии с размером объектов, на которые
ссылаются указатели.
Допускаются следующие операции с указателями: присваивание значения указателя
другому указателю того же типа, сложение и вычитание указателя и целого,
вычитание и сравнение двух указателей, ссылающихся на элементы одного и того
же массива, а также присваивание указателю нуля и сравнение указателя с
нулем. Все другие операции с указателями не допускаются. Нельзя складывать
два указателя, перемножать их, делить, сдвигать, выделять разряды; указатель
нельзя складывать со значением типа float или double; указателю одного типа
нельзя даже присвоить указатель другого типа, не выполнив предварительно
операции приведения (исключение составляют лишь указатели типа void *).
Стринговая константа, написанная в виде
"I am а string"
есть массив литер. Во внутреннем представлении этот массив заканчивается
«пустой» литерой '\0', по которой программа может найти конец стринга. Число
занятых ячеек памяти на одну больше, чем количество литер, помещенных между
двойными кавычками.
Чаще всего стринговые константы используются в качестве аргументов функций, как, например, в
printf("здравствуй, мир\n");
Когда такой литерный стринг появляется в программе, доступ к нему
осуществляется через литерный указатель; printf получает указатель на начало
массива литер. Точнее, доступ к стринговой константе осуществляется через
указатель на ее первый элемент.
Стринговые константы нужны не только в качестве аргументов функций. Если,
например, переменную pmessage описать как
char *pmessage
то присваивание
pmessage = "now is the time";
поместит в нее указатель на литерный массив, при этом сам стринг не копируется, копируется лишь указатель на него. Операции для работы со стрингом как с единым целым в Си не предусмотрены.
Существует важное различие между следующими определениями:
char amessage[] = "now is the time"; /* массив */ char *pmessage = "now is the time"; /* указатель */
amessage — это массив, имеющий такой объем, что в нем как раз помещается
указанная последовательность литер и '\0'. Отдельные литеры внутри массива
могут изменяться, но amessage всегда ссылается на одно и то же место памяти.
В противоположность ему pmessage есть указатель, инициализированный ссылкой
на стринговую константу. А значение указателя можно изменить, и тогда
последний будет ссылаться на что-либо другое. Кроме того, результат будет
неопределен, если вы попытаетесь изменить содержимое константы.

Дополнительные моменты, связанные с указателями и массивами, проиллюстрируем
на несколько видоизмененных вариантах двух полезных программ, взятых нами из
стандартной библиотеки. Первая из них, функция strcpy(s, t), копирует стринг t
в стринг s. Хотелось бы написать прямо s = t, но такой оператор копирует
указатель, а не литеры. Чтобы копировать литеры, нам нужно организовать
цикл. Первый вариант strcpy, с использованием массива, имеет следующий вид:
/* strcpy: копирует t в s; вариант с индексируемым массивом */
void strcpy(char *s, char *t)
{
int i;
i = 0;
while ((s[i] = t[i]) != '\0')
i++;
}
Для сравнения приведем версию strcpy с указателями:
/* strcpy: копирует t в s; версия 1 (с указателями) */
void strcpy(char *s, char *t)
{
while ((*s = *t) != '\0') {
s++;
}
Поскольку передаются лишь копии значений аргументов, strcpy может свободно
пользоваться параметрами s и t как своими локальными переменными. Они
должным образом инициализированы указателями, которые продвигаются каждый раз
на следующую литеру в каждом из массивов до тех пор, пока в копируемом
стринге t не встретится '\0'.
На практике strcpy так не пишут. Опытный программист предпочтет более
короткую запись:
/* strcpy: копирует t в s; версия 2 (с указателями) */
void strcpy(char *s, char *t)
{
while ((*s++ = *t++) != '\0')
;
}
Продвижение s и t здесь осуществляется в управляющей части цикла. Значением
*t++ является литера, на которую указывает переменная t перед тем, как ее
значение будет продвинуто; постфиксный оператор ++ не изменяет указатель t,
пока не будет взята литера, на которую он указывает. То же в отношении s,
сначала литера запомнится в позиции, на которую указывает старое значение s,
и лишь после этого значение переменной s увеличится. Пересылаемая литера
является одновременно и значением, которое сравнивается с '\0'. В итоге
копируются все литеры, включая и заключительную литеру '\0'.
Заметив, что сравнение с '\0' здесь лишнее (поскольку в Си ненулевое значение
выражения в условии трактуется и как его истинность), мы можем сделать еще
одно и последнее сокращение текста программы:
/* strcpy: копирует t в s; версия 3 (с указателями) */
void strcpy(char *s, char *t)
{
while (*s++ = *t++)
;
}
Хотя на первый взгляд то, что мы получили, выглядит как криптограмма, все же такая запись значительно удобнее, и следует освоить ее, поскольку в Си-программах вы будете с ней часто встречаться.
Что касается функции strcpy из стандартной библиотеки <string.h>, то она
возвращает в качестве своего результата еще и ссылку на новую копию стринга.
Вторая программа, которую мы здесь рассмотрим, это strcmp(s, t). Она
сравнивает литеры стрингов s и t и возвращает отрицательное, нулевое или
положительное значение, если стринг s соответственно лексикографически
меньше, равен или больше, чем стринг t. Результат получается вычитанием
первых несовпадающих литер из s и t.
/* strcmp: выдает <0 при s<t, 0 при s==t, >0 при s>t */
int strcmp(char *s, char *t)
{
int i;
for (i = 0; s[i] == t[i]; i++)
if (s[i] == '\0')
return 0;
return s[i] - t[i];
}
Та же программа с использованием указателей записывается так:
/* strcmp: выдает <0 при s<t, 0 при s==t, >0 при s>t */
int strcmp(char *s, char *t)
{
for ( ; *s == *t; s++, t++)
if (*s == '\0')
return 0;
return *s - *t;
}
Поскольку операторы ++ и -- могут быть и префиксными, и постфиксными,
возможны (хотя встречаются и не так часто) другие их сочетания с оператором
*. Например,
*--p
уменьшит p прежде, чем по этому указателю будет получена литера. Например,
следующие два выражения:
*p++ = val; /* поместить val в стек */ val = *--p; /* взять из стека значение и поместить в val */
являются стандартными записями для посылки в стек и взятия из стека. (См. разд. 4.3.)
Описания функций, упомянутых в этом разделе, а также ряда других стандартных
функций, работающих со стрингами, содержатся в головном файле <string.h>.
Используя указатели, напишите функцию strcat, которую мы
рассматривали в гл. 2 (функция strcat(s, t) копирует стринг t в конец
стринга s).
Напишите функцию strend(s, t), которая выдает 1, если стринг t
расположен в конце стринга s, и нуль в противном случае.
Напишите варианты библиотечных функций strncpy, strncat и
strncmp, которые оперируют с первыми литерами своих аргументов, число которых
не превышает n. Например, strncpy(t, s, n) копирует не более n литер t в s.
Полные описания этих функций содержатся в приложении B.
Отберите подходящие программы из предыдущих глав и упражнений
и перепишите их, используя вместо индексирования указатели. Подойдут, в
частности, программы getline (гл. 1 и 4), atoi, itoa
и их варианты (гл. 2, 3
и 4), reverse (гл. 3), а также strindex и getop (гл. 4).
Как и любые другие переменные, указатели можно группировать в массивы. Для
иллюстрации этого напишем программу, сортирующую в алфавитном порядке
текстовые строки; это будет упрощенный вариант программы sort системы UNIX.
В гл. 3 мы привели функцию сортировки по Шеллу, которая упорядочивает массив целых, а в гл. 4 улучшили ее, повысив быстродействие. Те же алгоритмы используются и здесь, однако теперь они будут обрабатывать текстовые строки, которые могут иметь разную длину и сравнение или перемещение которых невозможно выполнить за одну операцию. Нам необходимо выбрать некоторое представление данных, которое бы позволило удобно и эффективно работать с текстовыми строками произвольной длины.
Для этого воспользуемся массивом указателей на начала строк. Поскольку
строки в памяти расположены вплотную друг к другу, к каждой отдельной строке
доступ просто осуществлять через указатель на ее первую литеру. Сами
указатели можно организовать в виде массива. Одна из возможностей сравнить
две строки — передать указатели на них функции strcmp. Чтобы поменять местами
строки, достаточно будет поменять местами в массиве их указатели (а не сами
строки).

Здесь снимаются сразу две проблемы: одна — связанная со сложностью управления памятью, а вторая — с большими накладными расходами при перестановках самих строк.
Процесс сортировки распадается на три этапа:
чтение всех строк из ввода сортировка введенных строк печать их по порядку
Как обычно, выделим функции, соответствующие естественному делению задачи, и напишем главную программу, управляющую этими функциями. Отложим на время реализацию этапа сортировки и сосредоточимся на структуре данных и вводе-выводе.
Программа ввода должна прочитать и запомнить литеры всех строк, а также построить массив указателей на строки. Она, кроме того, должна подсчитать число введенных строк — эта информация понадобится для сортировки и печати. Так как функция ввода может работать только с конечным числом строк, то, если их введено слишком много, она будет выдавать некоторое значение, которое никогда не совпадет ни с каким количеством строк, например, -1.
Программа вывода занимается только тем, что печатает строки, причем в том порядке, в котором в массиве указателей на них расположены ссылки.
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /* максимальное число строк */
char *lineptr[MAXLINES]; /* указатели на строки */
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void qsort(char *lineptr[], int left, int right);
/* сортировка строк */
main()
{
int nlines; /* количество прочитанных строк */
if ((nlines = readlines(lineptr, MAXLINES)) >= 0) {
qsort(lineptr, 0, nlines-1);
writelines(lineptr, nlines);
return 0;
}
else {
printf("ошибка: слишком много строк\n");
return 1;
}
}
#define MAXLEN 1000 /* максимальная длина строки */
int getline(char *, int);
char *alloc(int);
/* readlines: чтение строк */
int readlines(char *lineptr[], int maxlines)
{
int len, nlines;
char *p, line[MAXLEN];
nlines = 0;
while ((len = getline(line, MAXLEN)) > 0)
if (nlines >= maxlines || (p = alloc(len)) == NULL)
return -1;
else {
line[len-1] = '\0'; /* убираем литеру \n */
strcpy(p, line);
lineptr[nlines++] = p;
}
return nlines;
}
/* writelines: печать строк */
void writelines(char *lineptr[], int nlines)
{
int i;
for (i = 0; i < nlines; i++)
printf("%s\n", lineptr[i]);
}
Функция getline взята из разд. 1.9.
Основное новшество здесь — декларация lineptr:
char *lineptr[MAXLINES];
в которой сообщается, что lineptr есть массив из MAXLINES элементов, каждый
из которых представляет собой указатель на char. Иначе говоря, lineptr[i] —
указатель на литеру, а *lineptr[i] — литера, на которую он указывает (первая
литера i-й строки текста).
Так как lineptr — имя массива, его можно трактовать как указатель, т.е. так
же, как мы это делали в предыдущих примерах, и writelines переписать
следующим образом:
/* writelines: печать строк */
void writelines(char *lineptr[], int nlines)
{
while (nlines-- > 0)
printf("%s\n", *lineptr++);
}
Вначале *lineptr ссылается на первую строку; каждое приращение указателя
приводит к тому, что *lineptr ссылается на следующую строку, и делается это
до тех пор, пока nlines не станет нулем.
Теперь, когда мы разобрались с вводом и выводом, можно приступить к
сортировке. Быструю сортировку, описанную в гл. 4, надо несколько
модифицировать: нужно изменить декларации, а операцию сравнения заменить
обращением к strcmp. Алгоритм остался тем же, и это дает нам определенную
уверенность в его правильности.
/* qsort: сортирует v[left]...v[right] по возрастанию */
void qsort(char *v[], int left, int right)
{
int i, last;
void swap(char *v[], int i, int j);
if (left >= right) /* ничего не делается, если */
return; /* в массиве менее двух элементов */
swap(v, left, (left + right )/2);
last = left;
for (i = left+1; i <= right; i++)
if (strcmp(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1);
qsort(v, last+1, right);
}
Небольшие поправки требуются и в программе перестановки.
/* swap: переставить v[i] и v[j] между собой */
void swap(char *v[], int i, int j)
{
char *temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
Так как каждый элемент массива v (т.е. lineptr) является указателем на
литеру, temp должен иметь тот же тип, что и v — тогда можно будет
осуществлять пересылки между temp и элементами v.
Напишите новую версию readlines, которая запоминала бы строки
в массиве, определенном в main, а не запрашивала память посредством программы
alloc. Насколько быстрее эта программа?
В Си имеется возможность задавать прямоугольные многомерные массивы, правда, на практике по сравнению с массивами указателей они используются значительно реже. В этом разделе мы продемонстрируем некоторые их свойства.
Рассмотрим задачу перевода даты «день–месяц» в «день года» и обратно.
Например, 1 марта — это 60-й день невисокосного или 61-й день високосного
года. Определим две функции для этих преобразований: функция day_of_year
будет преобразовывать месяц-день в день года, а month_day — день года в
месяц-день. Поскольку последняя функция вычисляет два значения, аргументы
месяц и день будут указателями. Так,
month_day(1988, 60, &m, &d)
установит в m число 2, а в d — значение 29 (29 февраля).
Нашим функциям нужна одна и та же информация, а именно таблица, содержащая числа дней каждого месяца. Так как для високосного и невисокосного годов эти таблицы будут различаться, проще иметь две отдельные строки в двумерном массиве, чем во время вычислений отслеживать особый случай с февралем. Массив и функции, выполняющие преобразования, имеют следующий вид:
static char daytab[2][13] = {
{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},
{0, 31, 29, 31, 30, 31, 30, 31. 31, 30, 31, 30, 31}
};
/* day_of_year: определяет день года по месяцу и дню */
int day_year(int year, int month, int day)
{
int i, leap;
leap = year % 4 == 0 && year % 100 != 0 || year % 400 == 0;
for (i = 1; i < mopth; i++)
day += daytab[leap][i];
return day;
}
/* month_day: определяет месяц и день по дню года */
void month_day(int year, int yearday, int *pmonth, int *pday)
{
int i, leap;
leap = year % 4 == 0 && year % 100 != 0 || year % 400 == 0;
for (i = 1; yearday > daytab[leap][i]; i++)
yearday -= daytab[leap][i];
*pmonth = i;
*pday = yearday;
}
Напоминаем, что арифметическое значение логического выражения (например,
выражения, с помощью которого вычислялось leap) равно нулю (ложь) или единице
(истина), так что мы можем использовать его как индекс в массиве daytab.
Массив daytab должен быть внешним по отношению к обеим функциям day_of_year и
month_day, так как он нужен и той и другой. Мы сделали его типа char, чтобы
проиллюстрировать законность применения типа char для малых целых.
Массив daytab — это первый массив из числа двумерных, с которыми мы еще не
имели дела. Строго говоря, в Си двумерный массив рассматривается как
одномерный массив, каждый элемент которого — также массив. Поэтому
индексирование изображается как
daytab[i][j] /* [строка][столбец] */
а не как
daytab[i,j] /* НЕВЕРНО */
Особенность двумерного массива в Си заключается лишь в форме записи, в остальном его можно трактовать почти так же, как в других языках. Элементы запоминаются строками, следовательно, при переборе их в том порядке, как они расположены в памяти, чаще будет изменяться самый правый индекс.
Массив инициализируется списком начальных значений, заключенным в фигурные
скобки; каждая строка двумерного массива инициализируется соответствующим
подсписком. Нулевой столбец добавлен в начало daytab лишь для того, чтобы
индексы, которыми мы будем пользоваться, совпадали с естественными номерами
месяцев от 1 до 12. Экономить пару ячеек памяти здесь нет никакого смысла, а
программа, в которой уже не надо корректировать индекс, выглядит более ясной.
Если двумерный массив передается функции в качестве аргумента, то декларация
соответствующего ему параметра должна содержать количество столбцов;
количество строк в данном случае несущественно, поскольку, как и прежде,
функции будет передана ссылка на массив строк, каждая из которых есть массив
из 13 значений типа char. В нашем частном случае имеем указатель на объекты,
являющиеся массивами из 13 значений типа char. Таким образом, если массив
daytab передается некоторой функции f, то эту функцию можно было бы
определить следующим образом:
f(char daytab[2][13]) { ... }
Вместо этого можно записать
f(char daytab[][13]) { ... }
поскольку число строк здесь не имеет значения, или
f(char (*daytab)[13]) { ... }
последняя запись декларирует, что параметр есть указатель на массив из 13
значений типа char. Скобки здесь необходимы, так как квадратные скобки []
имеют более высокий приоритет, чем *. Без скобок декларация
char *daytab[13]
определяет массив из 13 указателей на char. В более общем случае только
первое измерение (соответствующее первому индексу) можно не задавать, все
другие специфицировать необходимо.
В разд. 5.12 мы продолжим рассмотрение сложных деклараций.
В функциях day_of_year и month_day нет никаких проверок
правильности вводимых дат. Устраните этот недостаток.
Напишем функцию month_name(n), которая возвращает ссылку на стринг литер,
содержащий название n-го месяца. Эта функция идеальна для демонстрации
использования статического массива. Функция month_name имеет в своем личном
распоряжении массив стрингов, на один из которых она и возвращает ссылку.
Ниже покажем, как инициализируется этот массив имен.
Синтаксис задания начальных значений аналогичен синтаксису предыдущих инициализаций:
/* month_name: возвращает имя n-го месяца */
char *month_name(int n)
{
static char *name[] = {
"Неверный месяц",
"Январь", "Февраль", "Март",
"Апрель", "Май", "Июнь",
"Июль", "Август", "Сентябрь",
"Октябрь", "Ноябрь", "Декабрь"
};
return (n < 1 || n > 12) ? name[0] : name[n];
}
Декларация, определяющая name как массив указателей на литеры, такая же, как
и декларация lineptr в программе сортировки. Инициализатором служит список
стрингов, каждому из которых соответствует определенное место в массиве.
Литеры i-го стринга где-то размещены, и указатель на них запоминается в
name[i]. Так как размер массива name не специфицирован, компилятор вычислит
его по количеству заданных начальных значений.
Начинающие программировать на Си иногда не понимают, в чем разница между
двумерным массивом и массивом указателей типа name из приведенного примера.
Для двух следующих определений:
int a[10][20]; int *b[10];
записи a[3][4] и b[3][4] будут синтаксически правильными ссылками на
некоторое значение типа int. Однако только a является истинно двумерным
массивом: для двухсот элементов типа int будет выделена память, а вычисление
смещения элемента a[строка, столбец] от начала массива будет вестись по
формуле 20 x строка+столбец, учитывающей его прямоугольную природу. Для b же
определяются только 10 — указателей, причем без инициализации. Инициализация
должна задаваться явно — либо статически, либо в процессе счета. Предположим,
что каждый элемент b ссылается на двадцатиэлементный массив, в результате
где-то будут выделены пространство, в котором разместятся 200 значений типа
int, и еще 10 ячеек для указателей. Важное преимущество массива указателей в
том, что строки такого массива могут иметь разные длины. Таким образом,
каждый элемент b не обязательно ссылается на двадцатиэлементный вектор; один
может ссылаться на два элемента, другой — на пятьдесят, а некоторые и вовсе
могут ни на что не ссылаться.
Наши рассуждения здесь велись в отношении целых значений, однако чаще массивы
указателей используются для работы со стрингами литер, различающимися по
длине, как это было в функции month_name. Сравните определение массива
указателей и соответствующий ему рисунок:
char *name[] = {"Неправильный месяц", "Янв", "Февр", "Март"};
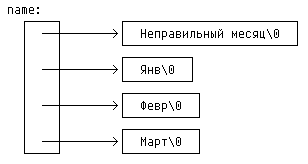
с определением и рисунком для двумерного массива:
char aname[][15] = {"Неправ. месяц", "Янв", "Февр", "Март"};
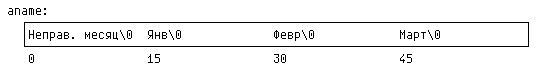
Перепишите программы day_of_year и month_of_year, используя
вместо индексов указатели.
В операционной среде, обеспечивающей поддержку Си, имеется возможность
передать аргументы или параметры запускаемой программе при помощи командной
строки. В момент вызова main получает два аргумента. В первом, обычно
называемом argc (сокращение от argument count), стоит количество аргументов,
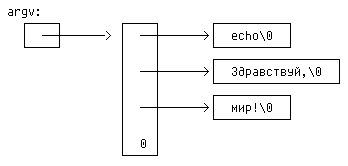
задаваемых в командной строке. Второй, argv (от argument vector), является
указателем на массив литерных стрингов, содержащих сами аргументы. Для работы
с этими стрингами обычно используются указатели нескольких уровней.
Простейший пример — программа echo («эхо»), которая печатает аргументы своей командной строки в одной строчке, отделяя их друг от друга пробелами. Так, команда
echo Здравствуй, мир!
напечатает
Здравствуй, мир!
По соглашению argv[0] есть имя вызываемой программы, так что значение argc
никогда не бывает меньше 1. Если argc равен 1, то в командной строке после
имени программы никаких аргументов нет. В нашем примере argc равен 3, и
соответственно argv[0], argv[1] и argv[2] есть стринги "echo", "Здравствуй,"
и "мир!". Первый необязательный аргумент — это argv[1], последний —
argv[argc-1]. Кроме того, стандарт требует, чтобы argv[argc] всегда был
пустым указателем.
Первая версия программы echo трактует argv как массив литерных указателей.
#include <stdio.h>
/* эхо аргументов командной строки: версия 1 */
main(int argc, char *argv[])
{
int i;
for (i = 1; i < argc; i++)
printf("%s%s", argv[i], (i < argc-1) ? " " : "");
printf("\n");
return 0;
}
Так как argv есть указатель на массив указателей, мы можем работать с ним как
с указателем, а не как с индексируемым массивом. Следующая программа основана
на продвижении argv, он продвигается так, что его значение в каждый отдельный
момент ссылается на очередной указатель на char; перебор указателей
заканчивается, когда исчерпан argc.
#include <stdio.h>
/* эхо аргументов командной строки; версия 2 */
main(int argc, char *argv[])
{
while (--argc > 0)
printf("%s%s", *++argv, (argc > 1) ? " " : "");
printf("\n");
return 0;
}
Аргумент argv — указатель на начало массива аргументных стрингов.
Использование в ++argv префиксного оператора ++ приведет к тому, что первым
будет напечатан argv[1], а не argv[0]. Каждое очередное продвижение указателя
дает нам следующий аргумент, на который ссылается *argv. В это же время
значение argc уменьшается на 1, и, когда оно станет нулем, все аргументы
будут напечатаны.
Инструкцию printf можно было бы написать и так:
printf((argc > 1) ? "%s " : "%s", ++argv);
Как видим, формат в printf может быть выражением.
В качестве второго примера возьмем программу поиска образца, рассмотренную в
разд. 4.1, и несколько усовершенствуем ее. Если вы помните, образец для
поиска мы «вмонтировали» глубоко в программу, а это, очевидно, не лучшее
решение. Построим нашу программу по аналогии с grep из UNIX`а, т.е. так,
чтобы образец для поиска задавался первым аргументом в командной строке.
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
/* find: печать строк с образцом заданным 1-м аргументом */
main(int argc, char *argv[])
{
char line[MAXLINE];
int found = 0;
if (argc != 2)
printf("Используйте в find образец\n'');
else
while (getline(line, MAXLINE) > 0)
if (strstr(line, argv[1]) != NULL) {
printf("%s", line);
found++;
}
return found;
}
Стандартная функция strstr(s, t) выдает указатель на первый найденный стринг t
в стринге s или NULL, если такого в s не оказалось. Ее описание хранится в
головном файле <string.h>.
Эту модель можно развивать и дальше, чтобы проиллюстрировать другие конструкции с указателями. Предположим, что мы вводим еще два необязательных аргумента. Один из них предписывает печатать все строки, кроме тех, в которых встречается образец; второй — перед каждой выводимой строкой печатать ее порядковый номер.
По общему соглашению для Си-программ в системе UNIX знак минус перед
аргументом может иногда играть роль необязательного признака или
дополнительного параметра. Так, -x служит признаком слова «кроме», которое
изменяет задание на противоположное, а -n указывает на потребность в
нумерации строк. Тогда, например, команда
find -x -n образец
напечатает все строки, в которых не найден указанный образец, и, кроме того, перед каждой строкой укажет ее номер.
Необязательные аргументы разрешается располагать в любом порядке, при этом лучше, чтобы остальная часть программы не зависела от числа представленных аргументов. Кроме того, пользователю было бы удобно, если бы он мог комбинировать необязательные аргументы, например, так:
find -nx образец
А теперь запишем нашу программу.
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
/* find: печать строк по образцу из 1-го аргумента */
main(int argc, char *argv[])
{
char line[MAXLINE];
long lineno = 0;
int c, except = 0, number = 0, found = 0;
while (--argc > 0 && (*++argv)[0] == '-')
while (c = *++argv[0])
switch (c) {
case 'x':
except = 1;
break;
case 'n':
number = 1;
break;
default:
printf("find: неверный парам. %c\n", c);
argc = 0;
found = -1;
break;
}
if (argc != 1)
printf("Используйте: find -x -n образец\n");
else
while (getline(line, MAXLINE) > 0) {
lineno++;
if ((strstr(line, *argv) != NULL) != except) {
if (number)
printf("%ld:", lineno);
printf("%s", line);
found++;
}
}
return found;
}
Перед получением очередного аргумента argc уменьшается на 1, а argv
«продвигается» на следующий аргумент. После завершения цикла при отсутствии
ошибок argc содержит количество еще не обработанных аргументов, а argv
указывает на первый из них. Таким образом, argc должен быть равен 1, а *argv
указывать на образец. Заметим, что *++argv является указателем на
аргумент-стринг, а (*++argv)[0] — его первой литерой, на которую можно
сослаться и другим способом: **++argv. Поскольку оператор индексации [] имеет
более высокий приоритет, чем * и ++, круглые скобки здесь обязательны, без
них запись трактовалась бы так же, как *++(argv[0]). Именно эту запись мы
применим во внутреннем цикле, где просматриваются литеры конкретного
аргумента. Во внутреннем цикле выражение *++argv[0] продвигает указатель
argv[0].
Потребность в более сложных указательных выражениях возникает не так уж часто. Но если такое случится, то, разбивая процесс вычисления указателя на два или три шага, вы облегчите восприятие этого выражения.
Напишите программу expr, интерпретирующую обратную польскую
запись выражения, задаваемую командной строкой, в которой каждый оператор и
операнд представлен отдельным аргументом. Например,
expr 2 3 4 + *
вычисляется так же, как выражение 2 * (3 + 4).
Усовершенствуйте программы entab и detab (см. упражнения
1.20 и 1.21) таким образом, чтобы через аргументы можно было задавать список
«стопов» табуляции.
Расширьте возможности entab и detab таким образом, чтобы при
обращении вида
entab -m +n
«стопы» табуляции начинались с m-й позиции и выполнялись через каждые n
позиций. Разработайте удобный для пользователя вариант поведения программы по
умолчанию (когда нет никаких аргументов).
Напишите программу tail, печатающую n последних введенных
строк. По умолчанию значение n равно 10, но при желании n можно задать с
помощью аргумента. Обращение вида
tail -n
печатает n последних строк. Программа должна вести себя осмысленно при любых
входных данных и любом значении n. Напишите программу так, чтобы наилучшим
образом использовать память; запоминание строк организуйте, как в программе
сортировки, описанной в разд. 5.6, а не на основе двумерного массива с
фиксированным размером строки.
В Си сама функция не является переменной, но можно определить указатель на
функцию и работать с ним, как с обычной переменной: присваивать, размещать в
массиве, передавать в качестве параметра функции, возвращать как результат из
функции и т.д. Для иллюстрации этих возможностей воспользуемся программой
сортировки, которая уже встречалась в настоящей главе. Изменим ее так, чтобы
при задании необязательного аргумента -n вводимые строки упорядочивались по
их числовому значению, а не в лексикографическом порядке.
Сортировка, как правило, распадается на три части: на сравнение, определяющее упорядоченность пары объектов; перестановку, меняющую порядок пары объектов на обратный, и сортирующий алгоритм, который осуществляет сравнения и перестановки до тех пор, пока все объекты не будут упорядочены. Алгоритм сортировки не зависит от операций сравнения и перестановки, так что, передавая ему различные функции сравнения и перестановки в качестве параметров, его можно настроить на различные критерии сортировки.
Лексикографическое сравнение двух строк выполняется функцией strcmp (мы уже
использовали эту функцию в ранее рассмотренной программе сортировки); нам
также потребуется программа numcmp, сравнивающая две строки как числовые
значения и возвращающая результат сравнения в том же виде, в каком его выдает
strcmp. Эти функции описываются перед main, а указатель на одну из них
передается функции qsort. Чтобы сосредоточиться на главном, мы упростили себе
задачу, отказавшись от анализа возможных ошибок при задании аргументов.
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /* максимальное число строк */
char *lineptr[MAXLINES]; /* указатели на строки текста */
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void qsort(void *lineptr[], int left, int right,
int (*comp)(void *, void *));
int numcmp(char *, char *);
/* сортировка строк */
main(int argc, char *argv[])
{
int nlines; /* количество прочитанных строк */
int numeric = 0; /* 1, если сорт, по числ. знач. */
if (argc > 1 && strcmp(argv[1], "-n") == 0)
numeric = 1;
if ((nlines = readlines(lineptr, MAXLINES)) >= 0) {
qsort((void **) lineptr, 0, nlines-1,
(int (*)(void*, void*)) (numeric ? numcmp : strcmp));
writelines(lineptr, nlines);
return 0;
}
else {
printf("введено слишком много строк\n");
return 1;
}
}
В обращениях к функциям qsort, strcmp и numcmp их имена трактуются как адреса
этих функций. Поэтому оператор & перед ними не нужен, как он был не нужен и
перед именем массива.
Мы написали qsort так, чтобы она могла обрабатывать данные любого типа, а не
только стринги литер. Как видно из прототипа, функция qsort в качестве своих
аргументов ожидает массив ссылок, два целых значения и функцию с двумя
аргументами — указателями. В качестве указателей — аргументов заданы
указатели обобщенного типа void *. Любой указатель можно привести к типу void
* и обратно без потери информации. Поэтому мы можем обратиться к qsort,
предварительно преобразовав аргументы в void *. Внутри функции сравнения ее
аргументы будут приведены к нужному ей типу. На самом деле эти преобразования
никакого влияния на представления аргументов не оказывают, они лишь
обеспечивают согласованность типов для компилятора.
/* qsort: сортирует v[left]... v[right] по возрастанию */
void qsort(void *v[], int left, int right,
int (*comp)(void *, void *))
{
int i, last;
void swap(void *v[], int, int);
if (left >= right) /* ничего не делается, если */
return; /* в массиве менее двух элементов */
swap(v, left, (left + right)/2);
last = left;
for (i = left+1; i <= right; i++)
if ((*comp)(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1, comp);
qsort(v, last+1, right, comp);
}
Повнимательней приглядимся к декларациям. Четвертый параметр функции qsort:
int (*comp)(void *, void *)
сообщает, что comp есть указатель на функцию, которая имеет два
аргумента-указателя и выдает результат типа int.
Использование comp в строке
if ((*comp)(v[i], v[left]) < 0)
согласуется с декларацией «comp — это указатель на функцию», и,
следовательно, *comp есть функция, а
(*comp)(v[i], v[left])
обращение к ней. Скобки здесь нужны, чтобы обеспечить правильную трактовку декларации; без них декларация
int *comp(void *, void *) /* НЕВЕРНО */
описывала бы comp, как функцию, возвращающую ссылку на int, а это совсем не
то, что требуется.
Мы уже рассматривали функцию strcmp, сравнивающую два стринга. Ниже
приведена функция numcmp, которая сравнивает два стринга, рассматривая их как
числа; предварительно они переводятся в числовые значения функцией atof.
#include <stdlib.h>
/* numcmp: сравнивает s1 и s2 как числа */
int numcmp(char *s1, char *s2)
{
double v1, v2;
v1 = atof(s1);
v2 = atof(s2);
if (v1 < v2)
return -1;
else if (v1 > v2)
return 1;
else
return 0;
}
Программу сортировки можно дополнить и другими возможностями; реализовать некоторые из них предлагается в качестве упражнений.
Модифицируйте программу сортировки, чтобы она реагировала на
параметр -r, указывающий, что объекты нужно сортировать в обратном порядке,
т.е. в порядке убывания. Обеспечьте, чтобы -r работал и вместе с -n.
Введите в программу необязательный параметр -f, задание
которого делало бы неразличимыми литеры нижнего и верхнего регистров
(например, a и A должны оказаться при сравнении равными).
Предусмотрите а программе необязательный параметр -d,
который заставит программу при сравнении учитывать только буквы, цифры и
пробелы. Организуйте программу таким образом, чтобы этот параметр мог
работать вместе с параметром -f.
Реализуйте в программе возможность работы с полями:
возможность сортировки по полям внутри строк. Для каждого поля предусмотрите
свой набор параметров. Предметный указатель этой книги (здесь имеется в виду
оригинал книги на английском языке. — Примеч. пер.) упорядочивался с
параметрами: -df для терминов и -n для номеров страниц.
Иногда Си ругают за синтаксис деклараций, особенно тех, которые содержат в себе указатели на функции. Таким синтаксис получился в результате нашей попытки сделать похожими записи объектов при их описании и использовании. В простых случаях этот синтаксис хорош, однако в сложных ситуациях он вызывает затруднения, поскольку декларации перенасыщены скобками и их невозможно читать слева направо. Проблему иллюстрирует различие следующих двух деклараций:
int *f(); /* f: фу-ция, возвращающая ук-ль на int */ int (*pf)(); /* pf: ук-ль на ф-цию, возвращающую int */
Приоритет префиксного оператора * ниже, чем приоритет (), поэтому во втором
случае скобки необходимы.
Хотя на практике по-настоящему сложные декларации встречаются редко, все же важно знать, как их понимать, а если потребуется, и как их конструировать.
Укажем хороший способ: декларации можно синтезировать, двигаясь небольшими
шагами с помощью typedef; этот способ рассмотрен в разд. 6.7. В настоящем
разделе на примере двух программ, осуществляющих преобразования правильных
Си-деклараций в соответствующие им словесные описания и обратно, мы
демонстрируем иной способ конструирования деклараций. Словесное описание
читается слева направо.
Первая программа, dcl, — более сложная. Она преобразует Си-декларации в
словесные описания так, как показано в следующих примерах:
char **argv
argv: указ. на указ. на char
int (*daytab)[13]
daytab: указ. на массив[13] из int
void *comp()
comp: функц. возвр. указ. на void
void (*comp)()
comp: указ. на функц. возвр. void
char (*(*x())[])()
x: функц. возвр. указ. на массив[] из указ. на функц.
возвр. char
char (*(*x[3])())[5]
x: массив[3] из указ. на функц. возвр. указ.
на массив[5] из char
Функция dcl в своей работе использует грамматику, специфицирующую декларатор.
Эта грамматика строго изложена в разд. 8.5 приложения A, а в упрощенном виде
записывается так:
dcl: optional *'s direct_dcl
direct_dcl: name
(dcl)
direct_dcl()
direct_dcl[optional size]
Говоря простым языком, dcl есть dlrect_dcl, перед которым может стоять *'s
(т.е. одна или несколько звездочек), где direct_dcl есть name (имя), или dcl
в скобках, или direct_dcl с последующей парой скобок, или direct_dcl с
последующей парой квадратных скобок, внутри которых может быть помещен размер
(size).
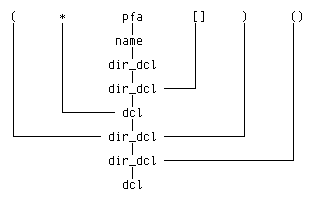
Эту грамматику можно использовать для грамматического разбора деклараций. Рассмотрим, например, такой декларатор:
(*pfa[])()
Имя pfa будет классифицировано как name и, следовательно, как direct_dcl.
Затем pfa[] будет распознано как direct_dcl, а *pfa[] — как dcl и,
следовательно. (*pfa[]) есть direct_dcl. Далее (*pfa[])() есть direct_dcl и,
таким образом, dcl. Этот грамматический разбор можно проиллюстрировать
деревом разбора (здесь direct_dcl обозначено более коротко, а именно
dir_dcl):
Сердцевиной программы обработки декларатора является пара функций dcl и
dirdcl, осуществляющих грамматический разбор декларации согласно приведенной
грамматике. Поскольку грамматика определена рекурсивно, эти функции
обращаются друг к другу рекурсивно, по мере распознавания отдельных частей
декларации. Метод, примененный в обсуждаемой программе для грамматического
разбора, называется рекурсивным спуском.
/* dcl: разбор декларатора */
void dcl(void)
{
int ns;
for (ns = 0; gettoken() == '*'; ) /* подсчет звездочек */
ns++;
dirdcl();
while (ns-- > 0)
strcat(out, " указ. на");
}
/* dirdcl: разбор непосредственного декларатора */
void dirdcl(void)
{
int type;
if (tokentype == '(') { /* (dcl) */
dcl();
if (tokentype != ')')
printf(" ошибка: пропущена )\n");
}
else if (tokentype == NAME) /* имя переменной */
strcpy(name, token);
else
printf("ошибка: должно быть name или (dcl)\n");
while ((type = gettoken()) == PARENS || type == BRACKETS)
if (type == PARENS)
strcat(out, " функц. возвр.");
else {
strcat(out, " массив");
strcat(out, token);
strcat(out, " из");
}
}
Приведенные программы служат только иллюстративным целям и не вполне надежны.
Что касается dcl, то ее возможности существенно ограничены. Она может
работать только с простыми типами вроде char и int и не справляется с типами
аргументов в функциях и с квалификаторами подобными const. Лишние пробелы для
нее опасны. Она не предпринимает никаких мер по выходу из ошибочной ситуации,
и поэтому неправильные декларации также противопоказаны ей. Устранение этих
недостатков мы оставляем до упражнений.
Ниже приведены глобальные переменные и главная программа.
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define MAXTOKEN 100
enum { NAME, PARENS, BRACKETS };
void dcl(void);
void dirdcl(void);
int gettoken(void);
int tokentype; /* тип последней лексемы */
char token[MAXTOKEN]; /* текст последней лексемы */
char name[MAXTOKEN]; /* имя */
char datatype[MAXTOKEN]; /* тип = char, int и т.д. */
char out[1000]; /* выдаваемый текст */
/* преобразование декларации в словесное описание */
main()
{
while (gettoken() != EOF) { /* 1-я лексема в строке */
strcpy(datatype, token); /* это тип данных */
out[0] = '\0';
dcl(); /* разбор остальной части строки */
if (tokentype != '\n')
printf("синтаксическая ошибка\n");
printf("%s: %s %s\n", name, out, datatype);
}
return 0;
}
Функция gettoken пропускает пробелы и табуляции и затем получает следующую
лексему из ввода; «лексема» — это имя, или пара круглых скобок, или пара
квадратных скобок (быть может, с помещенным в них числом), или любая другая
единичная литера.
/* возвращает следующую лексему */
int gettoken(void)
{
int c, getch(void);
void ungetch(int);
char *p = token;
while ((c = getch()) == ' ' || c == '\t')
;
if (c == '(') {
if ((c = getch()) == ')') {
strcpy(token, "()");
return tokentype = PARENS;
}
else {
ungetch(c);
return tokentype = '(';
}
}
else if (c == '[') {
for (*p++ = c; (*p++ = getch()) != ']'; )
;
*p ='\0';
return tokentype = BRACKETS;
}
else if (isalpha(c)) {
for (*p++ = c; isalnum(c = getch()); )
*p++ = c;
*p = '\0';
ungetch(c);
return tokentype = NAME;
}
else
return tokentype = c;
}
Функции getch и ungetch были рассмотрены в гл. 4.
Обратное преобразование реализуется легче, особенно если не придавать
значения тому, что будут генерироваться лишние скобки. Программа undcl
превращает фразу типа «x есть функция, возвращающая указатель на массив
указателей на функции, возвращающие char», которую мы будем представлять в
виде
x () * [] () char
в декларацию
char (*(*x())[])()
Сокращенная запись словесного описания позволяет воспользоваться функцией
gettoken. Функция undcl использует те же самые внешние переменные, что и dcl.
/* undcl: преобразует словесное описание в декларацию */
main()
{
int type;
char temp[MAXTOKEN];
while (gettoken() != EOF) {
strcpy(out, token);
while ((type = gettoken()) != '\n')
if (type == PARENS || type == BRACKETS)
strcat (out, token);
else if (type == '*') {
sprintf(temp, "(*%s)", out);
strcpy(out, temp);
}
else if (type == NAME) {
sprintf(temp, "%s %s", token, out);
strcpy(out, temp);
}
else
printf("неверный элемент %s в фразе\n", token)
printf("%s\n", out);
}
return 0;
}
Видоизмените dcl таким образом, чтобы она нормально
обрабатывала ошибки во входной информации.
Модифицируйте undcl так, чтобы она не генерировала лишних
скобок.
Расширьте возможности dcl: функция должна справляться с
описателями типов ее аргументов, квалификаторами const и т.д.